Korean Crop Genetic Coefficient Digitization Strategy
Genetic Coefficients Digitization & Inference System Strategy
1Overview & Objectives
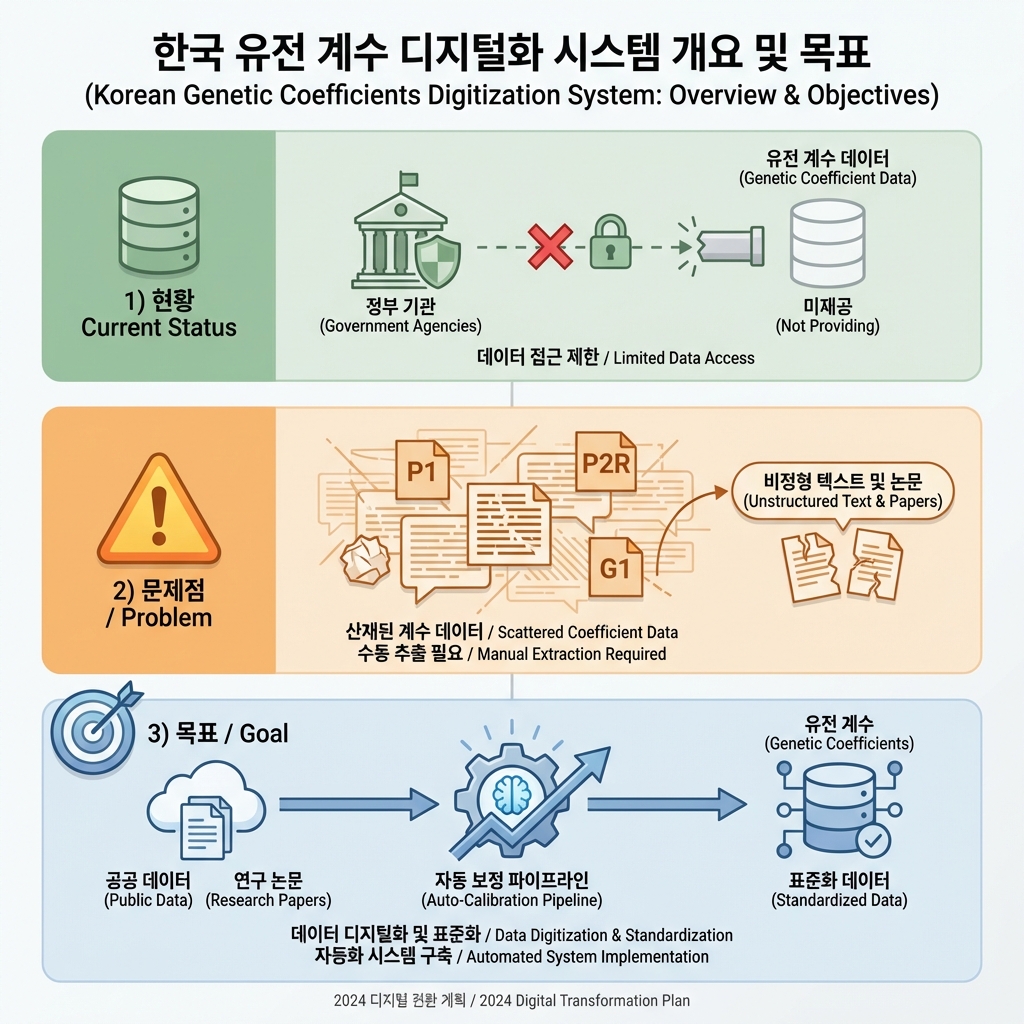
Current Status
Government agencies such as the Rural Development Administration (RDA) do not provide data in a 'Genotype Parameter' format that can be directly applied to crop models like DSSAT/APSIM.
Problem
Coefficients such as P1 (basic vegetative phase), P2R (photoperiod sensitivity), and G1 (kernel number) are essential for simulation, but currently exist only as unstructured text (papers, reports) or fragmented public data (phenotype information).
Objective
Collect public data (phenotype + weather information) and reverse-engineer it to build an 'Auto-Calibration Pipeline' that automatically generates and calibrates genetic coefficients for Korean cultivars.
2Data Acquisition Strategy
A 3-tier hierarchical approach based on data precision and accessibility.
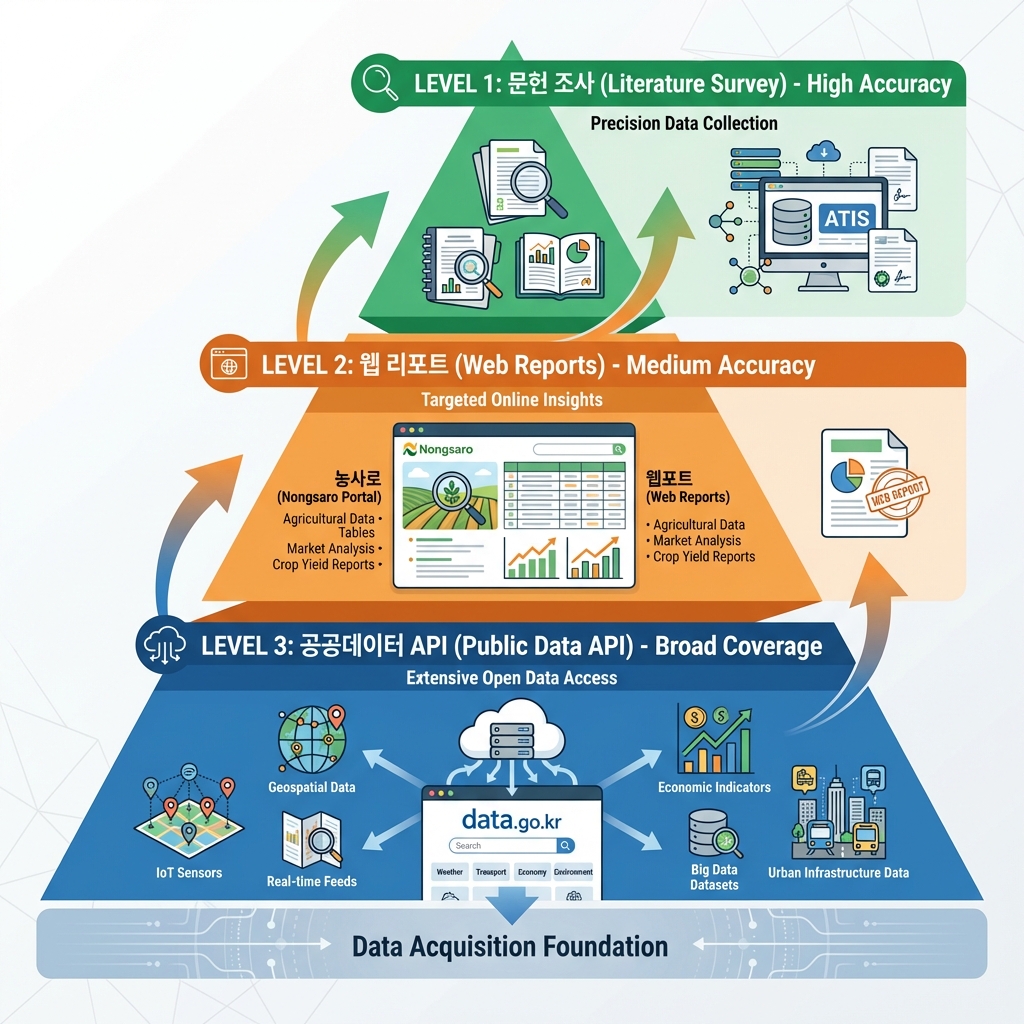
Level 1: Baseline Data Acquisition - Literature Review High Accuracy
The most accurate but hardest to automate. Used as 'Seed Data' for the system.
Sources
- • RDA Agricultural Science & Technology Information System (ATIS)
- • Agricultural Science Library
Target
Previously published research papers and reports on 'major cultivars (Sindongjin, Samkwang, Saenuri, etc.)'
Collection Strategy
- Search Keywords: "Rice growth simulation", "DSSAT cultivar parameters", "Parameter Calibration"
- OAS Application: Hard-code acquired coefficient values into the database as 'Standard Reference'. Use as a benchmark for inference of other cultivars.
Level 2: Detailed Characteristic Data - Web Reports Medium Accuracy
Data is extracted via parsing from text-format detailed reports.
Source
Nongsaro Portal > Cultivar Information
Target
Breeding history, key characteristics tables (including accumulated temperature and growth period data)
Collection Strategy
- Operate C#-based web crawlers (Selenium/HtmlAgilityPack)
- Extract and structure heading date, maturity date, plant height, and yield data from HTML tables
Level 3: Bulk Basic Data - Public Data APIs Broad Coverage
The broadest range of cultivar data can be collected through automation.
Public Data Portal (data.go.kr)
| Data Name | Description | Provider |
|---|---|---|
| Genetic Resources / Characteristics | Agricultural genetic resource information | National Institute of Agricultural Sciences |
| Cultivar Detail Information | RDA cultivar information | Application/Registration focused |
| New Cultivar List | New cultivar seed distribution status | National Institute of Crop Science |
Collection Strategy
- Periodically (e.g., monthly) update new cultivar information through the OAS Data Ingestion Module
- Extract date and numeric data from 'Key Characteristics' text fields using regex
3Implementation Plan
The core logic that takes 'Phenotype data' as input and outputs 'Genotype coefficients'.
3.1 System Architecture
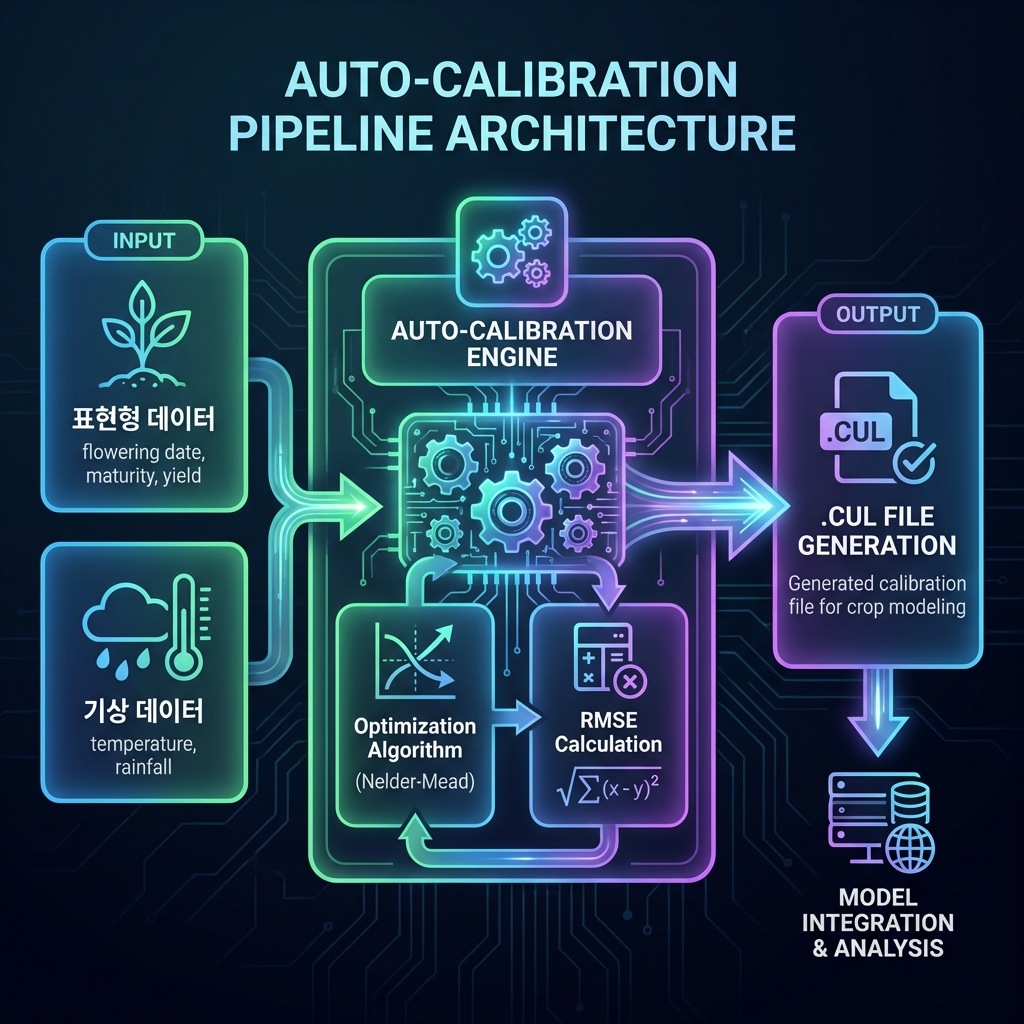
This system operates as a sub-module within the OAS Core engine (.NET).
Input (Ground Truth)
Cultivar-specific 'observed heading date', 'observed maturity date', 'observed yield' extracted from public data
Input (Environment)
'Historical weather data' for the relevant year/region collected via KMA API
Process
Coefficient optimization through the Auto-Calibration Engine
Process (Auto-Calibration Engine)
- Run simulation with initial genetic coefficients (baseline values from Level 1)
- Calculate error (RMSE) between predicted and observed values
- Fine-tune coefficients (P1, P2R, etc.) using optimization algorithms (Nelder-Mead, etc.) until error converges to 0
Output
Optimized .CUL (Cultivar) file for the target cultivar
Inference Engine Design Document
View the detailed design and implementation strategy for the Korean Plant Genetic Coefficient Inference Engine.
3.2 Phased Implementation Roadmap
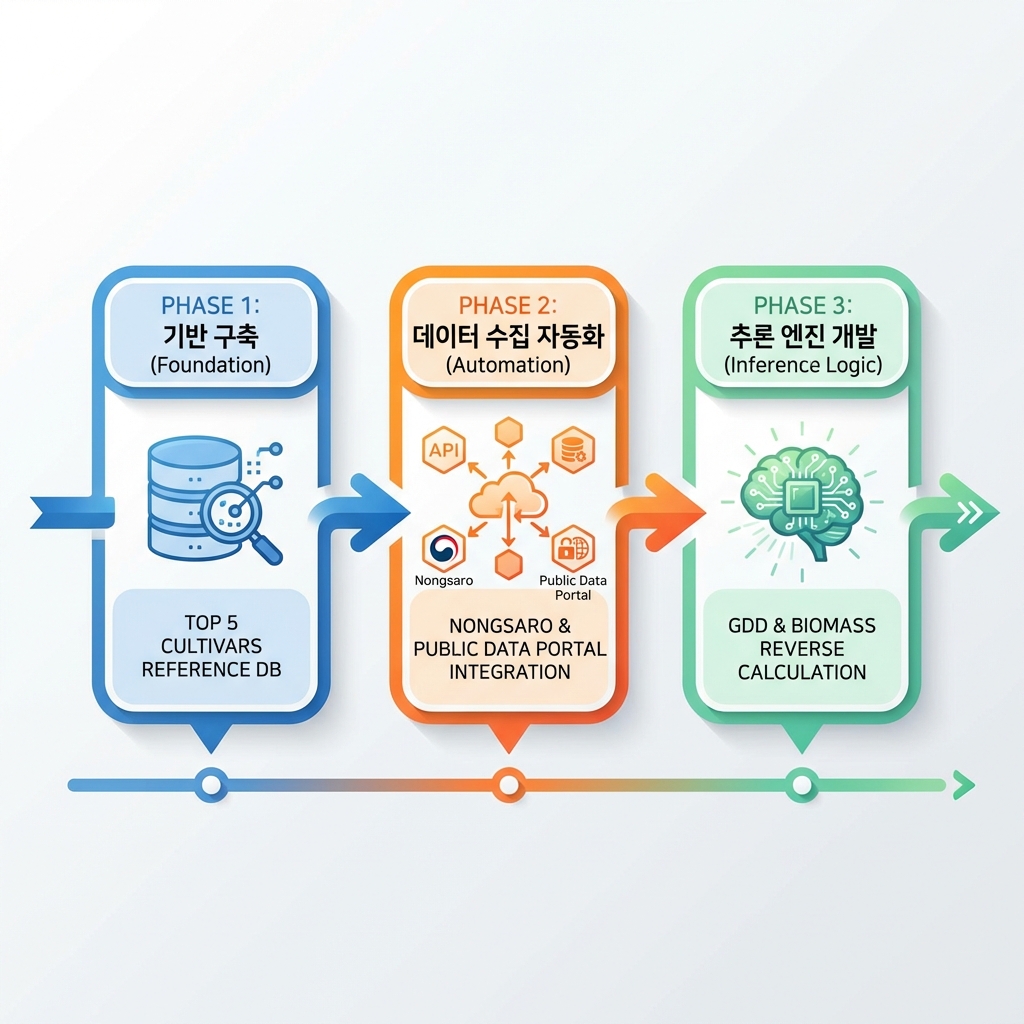
Phase 1Foundation
Goal: Build a Reference DB for major cultivars (Top 5) based on ATIS literature data
Action Items:
- Collect existing research papers for major cultivars (Sindongjin, Chucheong, Samkwang, etc.) and manually enter coefficients
- Verify that the OAS engine can read these coefficients and successfully perform simulation (heading date prediction)
Phase 2Data Collection Automation
Goal: Develop Nongsaro and Public Data Portal API integrations
Action Items:
- Implement C# HttpClient-based Public Data Portal API integration module
- Implement a parser to convert collected text data (e.g., "August 15 heading") to DateTime and Day of Year (DOY)
- Load collected data into the OAS.Data.Phenotypes table
Phase 3Inference Engine Development (Inference Logic)
Goal: Implement logic to automatically generate genetic coefficients by reverse-engineering phenotype data
Action Items:
- GDD Reverse Calculation: Implement a function that queries weather data during the (heading date − transplanting date) period to automatically calculate accumulated temperature (P1)
- Biomass Reverse Calculation: Implement logic to estimate photosynthesis efficiency and distribution coefficients (G1, G2) based on 'plant height' and 'yield' data
4Verification Strategy
The process of verifying whether the inferred coefficients are valid.
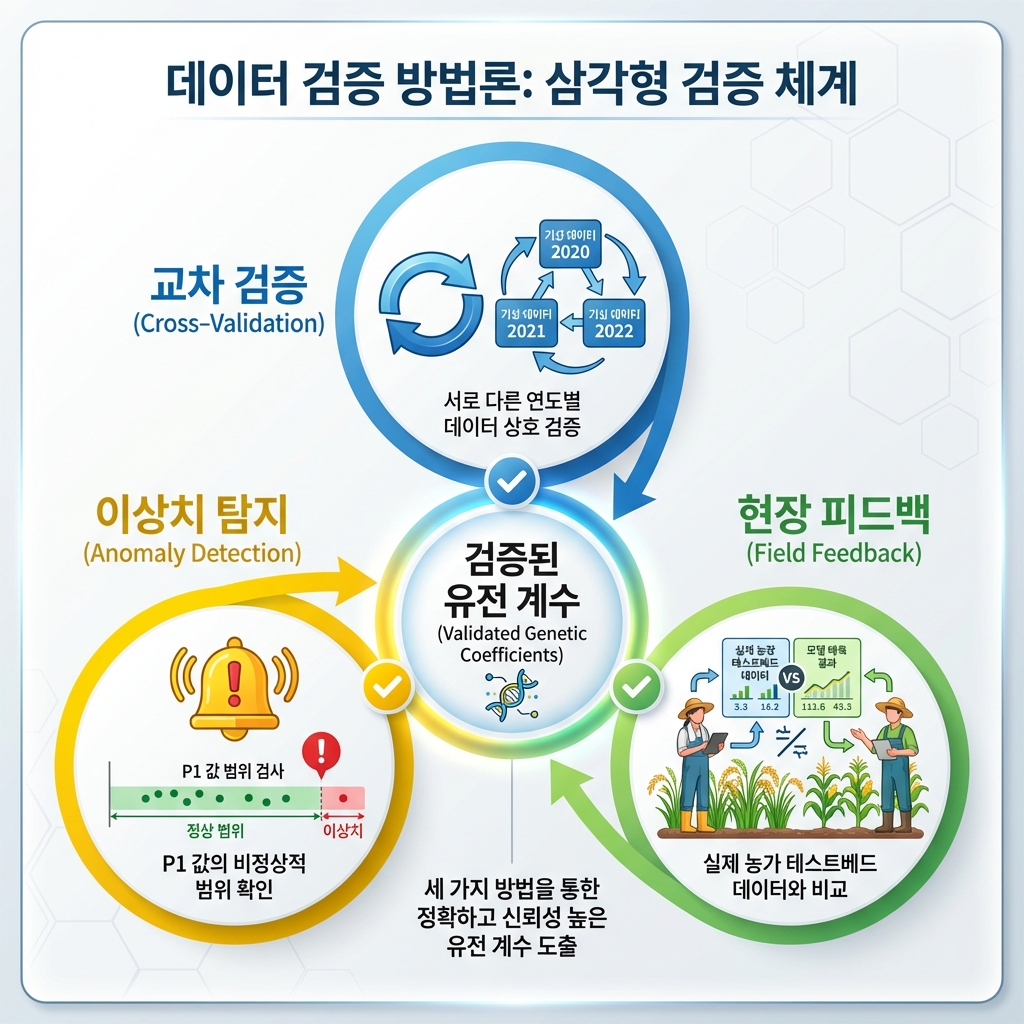
Cross-Validation
Verify that results match observed heading dates when weather data from different years (not used for inference) is input
Outlier Detection
Generate system alerts and request manual review when calculated P1 values fall outside the typical range for rice cultivars
Field Feedback
Continuously calibrate coefficients by comparing with growth data from actual farm testbeds (OAS pilot farms)
5Recommendations & Expected Benefits
Data Assetization
Transform scattered text information into 'actionable digital assets' to secure OAS's unique competitive advantage
Scalability
The same pipeline can be extended to other crops beyond rice, including soybean, corn, and more
Development Priority
Recommended to first complete Phase 1 (hard-code top 5 cultivars) to get the simulation engine running, then expand supported cultivars through Phase 2 (API integration)